이번 글에서는 Google에서 발행한 Agents 백서를 바탕으로 Agent(에이전트)의 핵심 구성 요소, 작동 방식 등에 대해 살펴보겠습니다.
목차
Google's AI White Paper "Agents"
2024년 9월 Julia Wiesinger, Patrick Marlow, Vladimir Vuskovic은 "Agents" 백서를 발표했습니다. 이 백서는 2025년 1월 초 X.com에 게재되었으며, AI Agent가 무엇인지, AI 모델과 어떻게 다른지를 설명합니다.
Agent란 무엇인가?
생성형 AI Agent는 주어진 목표를 달성하기 위해 주변 환경을 관찰하고, 사용할 수 있는 도구를 활용하여 자율적으로 행동하는 애플리케이션을 의미합니다. 이러한 Agent는 적절한 목표와 지침만 주어지면 인간의 개입 없이도 스스로 판단하고 행동할 수 있습니다. 나아가 인간이 구체적인 지시를 내리지 않아도 목표 달성을 위해 필요한 다음 단계를 능동적으로 계획하고 실행하는 특징이 있습니다.
백서에서는 현재 시점에서 생성형 AI 모델이 구성할 수 있는 특정 유형의 Agent를 다룹니다. Agent가 어떻게 작동하는지를 이해하기 위해서는 Agent의 행동, 의사결정 과정을 이끄는 'Cognitive Architecture (인지 아키텍처)'를 살펴볼 필요가 있습니다. 이 인지 아키텍처는 여러 구성 요소를 어떻게 조합하느냐에 따라 다양한 형태를 띠지만, 기본적으로 세 가지 핵심 요소가 Agent의 작동 원리를 결정합니다.

Agent의 핵심 구성 요소
Agent의 동작을 구동하는 핵심 구성 요소는 Model, Tools, Orchestration Layer 로 구성되어 있습니다:
Model
Agent에서 '모델'은 언어 모델(LM)을 의미하며, Agent가 의사결정을 내리고 행동을 계획하는 중심 역할을 합니다. ReAct, Chain-of-Thought, Tree-of-Thoughts 등과 같은 추론·논리 프레임워크를 따를 수 있으며, Agent의 특성에 맞춰 일반 목적용, 멀티모달, 혹은 특정 분야에 맞게 미세 조정된 모델을 사용할 수 있습니다.
Tools
대형 언어 모델은 텍스트·이미지 생성 능력이 뛰어나지만 외부 세계와 직접 소통하는 능력은 제한적입니다. 이런 한계를 보완하는 것이 도구로, Agent가 외부 데이터와 서비스를 활용할 수 있도록 해줍니다. 예를 들어, API를 사용해 데이터베이스를 업데이트하거나 날씨 정보를 조회하여 사용자에게 더 정확한 추천을 제시할 수 있습니다. 이처럼 도구를 통해 Agent는 보다 확장된 기능을 수행할 수 있으며, Retrieval-Augmented Generation(RAG) 같은 특수 시스템도 구현 가능합니다.
Orchestration Layer
Orchestration Layer는 Agent가 정보를 입력받고 내부적으로 추론을 수행한 뒤, 그 결과에 따라 다음 행동을 결정하는 과정을 순환 구조로 제어하는 역할을 합니다. 이 순환은 Agent가 목표를 달성하거나 중지 조건에 도달할 때까지 이어집니다. Agent의 복잡도와 수행하는 작업에 따라 이 레이어의 구조도 달라지며, 간단한 규칙 기반 결정부터 고도화된 기계학습 알고리즘 또는 확률적 추론 기법이 포함된 복합 로직까지 다양한 형태로 구현될 수 있습니다.
Agent와 Model의 차이점
Agent와 Model은 몇 가지 중요한 차이점이 있습니다.

- 지식 범위: Model은 학습 데이터에 기반해 지식이 제한되는 반면, Agent는 도구를 활용해 외부 시스템과 연결함으로써 지식 범위를 확장할 수 있습니다.
- 추론 방식: Model 은 주어진 입력(쿼리)에 대해 단일한 추론이나 예측을 수행하며, 세션 히스토리나 컨텍스트 관리는 제한적입니다. Agent는 세션 히스토리를 활용해 다중 턴 추론과 예측을 수행하고, Orchestration Layer에서 사용자 쿼리와 의사 결정을 종합적으로 처리합니다.
- 도구: Model은 자체적으로 네이티브 도구 기능이 없지만, Agent는 이러한 도구 기능을 네이티브로 구현해 외부 정보를 조회하거나 시스템을 제어할 수 있습니다.
- 로직: Model은 간단한 질문·프롬프트나 CoT, ReAct 같은 추론 프레임워크를 사용할 수 있지만, Agent는 이러한 프레임워크를 Native Cognitive Architecture(네이티브 인지 구조)로 통합해 더욱 복합적인 추론이 가능합니다.
Cognitive architectures: 작동 방식
Agent를 요리사에 비유하면, 요리사가 손님 주문과 재료 상태 등을 확인하고, 맛있는 요리를 만들기 위해 준비·실행·조정 단계를 반복하는 과정과 같습니다. Agent 역시 정보를 받아들이고(Observation), 내부적으로 추론한 뒤(Thought), 적절한 행동(Action)을 결정하고 실행 결과를 관찰하여(Observation) 최종 답변을 제공합니다.
이 과정을 보다 효율적으로 수행하기 위해, Agent는 Orchestration Layer 내에서 ReAct, Chain-of-Thought(CoT), Tree-of-Thoughts(ToT) 같은 프롬프트 엔지니어링 프레임워크를 사용합니다.
- ReAct: 모델이 "질문 → 생각(Thought) → 행동(Action) → 도구 사용(Observation) → 최종 답변" 순으로 반복하며, 필요한 도구를 선택해 실제 정보를 조회하거나 계산하게 합니다.
- CoT (Chain of Thought): 중간 추론 과정을 거치도록 해 모델이 단계별로 사고 과정을 명시적으로 밝히며 답변의 정확도를 높입니다.
- ToT (Tree of Thoughts): 다양한 사고 경로를 탐색해볼 수 있게 하는 전략으로, 특히 탐색과 예측이 중요한 과제에서 유용합니다.
Chain of Thought Prompting
Prompt Engineering Guide(https://www.promptingguide.ai/) 내용을 참고해서 작성하거나, 번역한 내용입니다. Chain of Thought Prompting (생각의 사슬 프롬프팅) LLM 에게 이유에 대해 설명하도록 만드는 방법입니다.
wide-shallow.tistory.com
Tree of Thoughts
Prompt Engineering Guide(https://www.promptingguide.ai/) 내용을 참고해서 작성하거나, 번역한 내용입니다. Tree of Thoughts(ToT) 탐구나 전략적인 예측이 필요한 복잡한 작업들을 해결하기 위해, 기존의 프롬프팅
wide-shallow.tistory.com
Agent는 모델의 추론 능력과 적절한 도구 활용, 그리고 반복적인 의사결정 과정을 통해 정확하고 신뢰도 높은 답변을 생성할 수 있습니다. 이러한 구조는 요리사가 재료와 레시피를 토대로 끊임없이 결과를 점검하고 조정하여 최상의 요리를 만들어내는 과정과 비슷합니다.
Tools: 외부 세계로 연결
언어 모델은 학습 데이터 내에서 정보를 처리하는 데는 뛰어나지만, 실제 세계와 직접 상호 작용하거나 새로운 데이터를 자체적으로 획득하지 못하는 한계가 있습니다. 이 제약을 극복하기 위해서는 도구(Functions, Extensions, Data Stores, Plugins 등)와 연결해 실시간으로 외부 시스템이나 데이터를 활용할 수 있도록 해야 합니다.
Extensions
Agent와 API 사이를 표준화된 방식으로 연결해 주는 Extensions의 개념을 설명합니다.

예를 들어 항공편 예약 에이전트를 구축하려고 할 때, 직접 코드로 사용자 입력을 분석하고 API를 호출하는 방식을 사용할 수도 있지만, 이는 예외 케이스가 많고 확장성이 떨어집니다. 대신, Extension을 통해
- Agent가 API를 어떻게 사용해야 하는지 예시로 학습시키고,
- API 호출에 필요한 매개변수나 인자를 알려줄 수 있습니다.
Agent는 런타임에 사용자의 요청을 보고 어떤 Extension을 사용할지 스스로 결정합니다.

이는 개발자가 문제 해결을 위해 여러 API를 선택적으로 사용하는 것과 유사합니다. 구글 Flights Extension을 활성화하고 "다음 주 금요일에 오스틴에서 취리히로 가는 항공편 찾아줘"라고 묻는 예시처럼, Extension을 통해 Agent가 자동으로 적절한 API를 호출하도록 유도할 수 있습니다.
Functions
Agent에서의 Function 개념을 설명하며, 소프트웨어 개발에서의 함수와 유사하게 특정 작업을 수행하는 코드 조각으로 재사용할 수 있다는 점을 강조합니다.

그러나 다음과 같은 차이점이 있습니다.
- 모델이 Function 호출 및 인자를 결정하지만, 실제 API 요청은 수행하지 않습니다.
- Function은 클라이언트 측(예: 프론트엔드, 별도의 미들웨어 등)에서 실행되며, 반면 Extension은 Agent 측에서 실행됩니다.
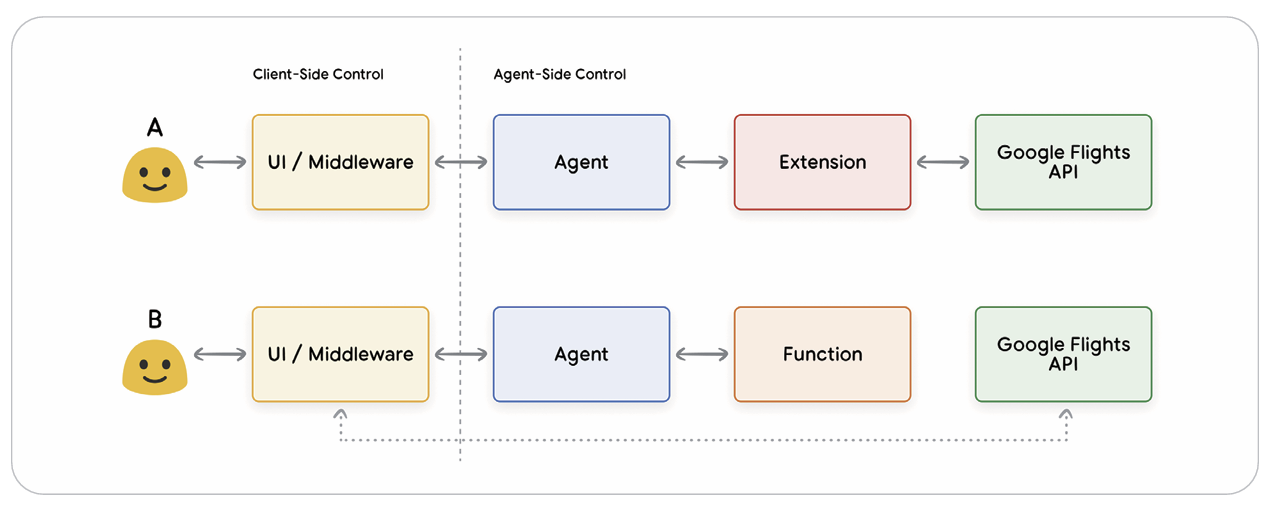
예를 들어 항공편 예약 시나리오에서, Extension을 사용하면 Agent가 직접 API를 호출하지만, Function 방식을 사용하면 API 호출 로직은 Agent 바깥(클라이언트 측)으로 옮겨집니다.
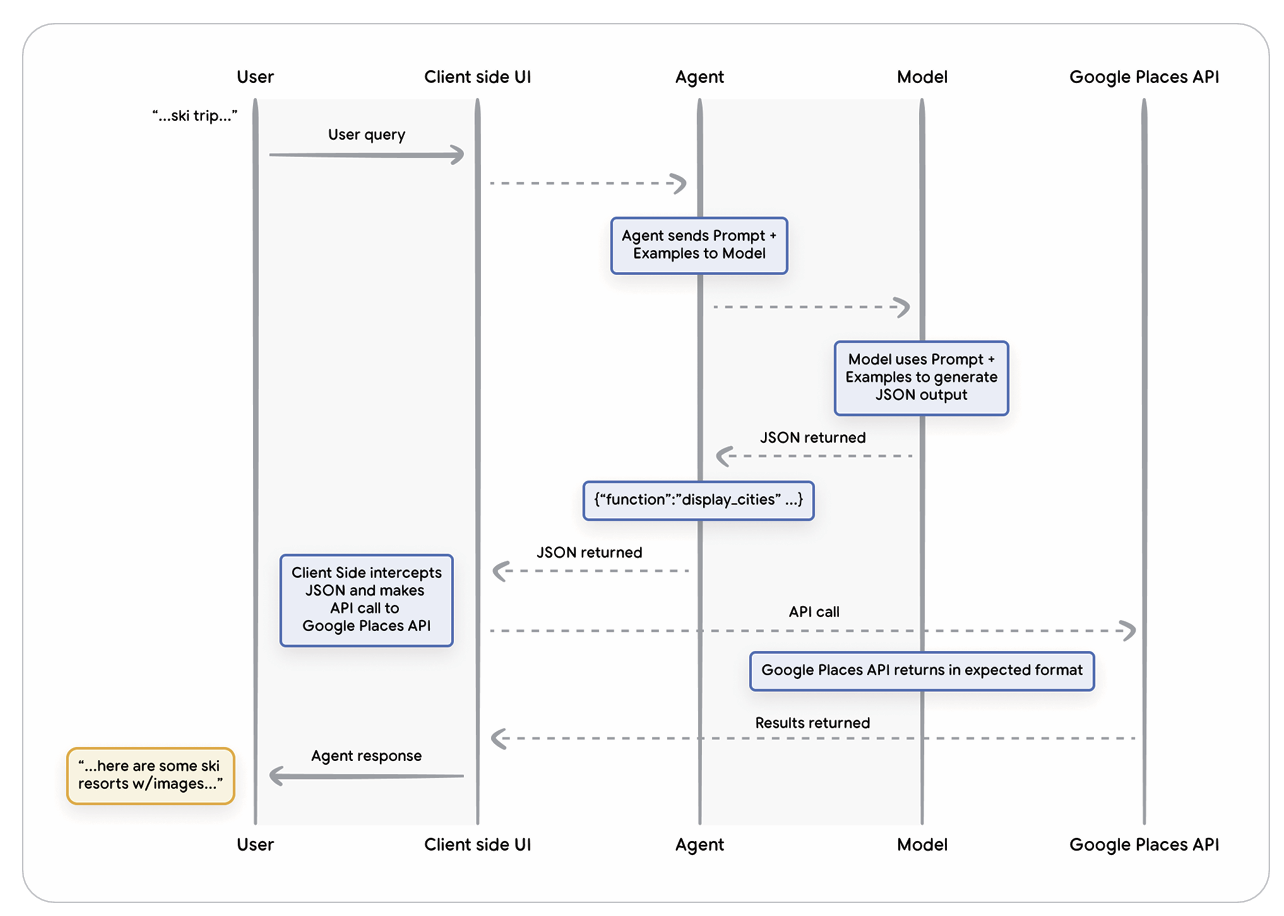
이는 보안, 인증, 추가 데이터 가공 요구사항, 외부 인프라에 대한 접근 제약 등 다양한 이유로 Function 방식을 선호할 수 있음을 보여줍니다.
Data stores
모델이 학습 데이터만으로는 최신 정보를 반영하기 어렵다는 한계를 해결하기 위해 Data Store를 활용하는 개념을 다룹니다.
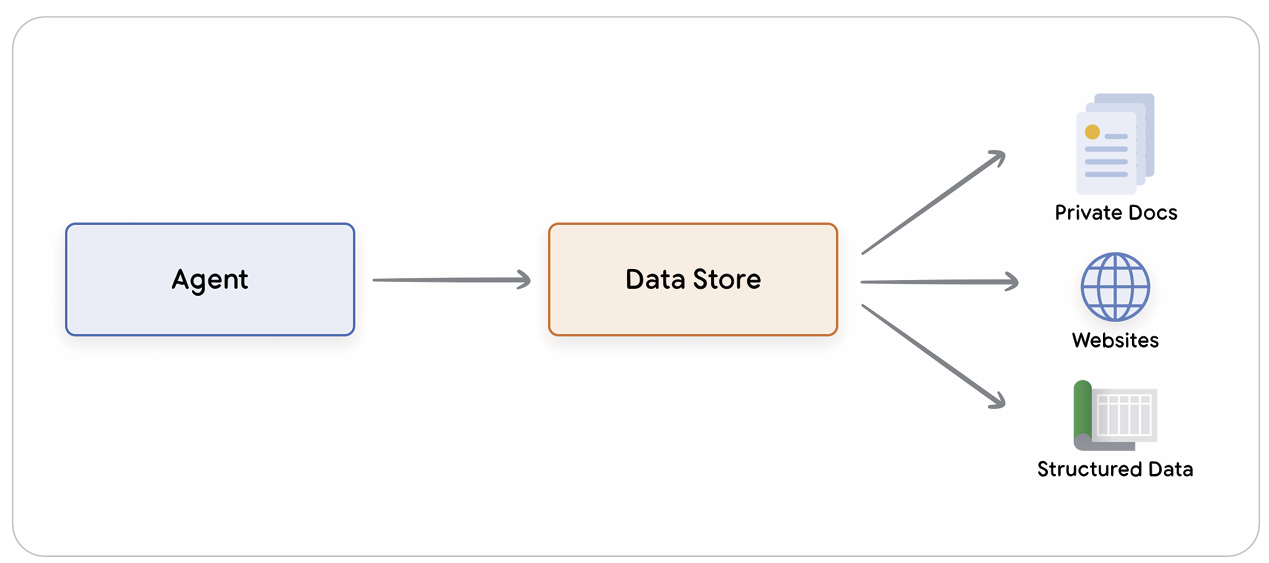
- 일반적으로 언어 모델은 학습 시점 이후 지식이 업데이트되지 않지만, Data Store를 사용하면 모델이 최신 정보를 검색해 활용할 수 있습니다.
- 예컨대, 개발자는 스프레드시트나 PDF 형식의 문서를 Data Store에 그대로 업로드할 수 있으며, 이는 벡터 임베딩 형태로 변환되어 Agent가 필요한 정보를 검색하고 사용자 응답에 반영합니다.
- 이를 통해 시간 소모적인 데이터 변환, 모델 재학습, 파인튜닝 없이도 Agent가 항상 최신 상태의 데이터를 참조하여 정확하고 시의성 있는 답변을 제공할 수 있습니다.
타겟 학습을 통해 모델 성능 향상
모델이 도구를 적절히 활용해 원하는 결과를 얻도록 하는 세 가지 학습 접근 방법을 소개합니다:
In-context Learning
- 모델에 프롬프트, 도구, Few-Shot 등을 제공하여 실시간으로 학습·추론하게 하는 방법
- 기본적으로 모델이 기존에 학습한 일반 지식에 기반하지만, 주어진 예시와 도구를 통해 즉석에서 특정 작업에 최적화된 결과를 낼 수 있음
Retrieval-based In-context Learning
- 외부 데이터 스토어에서 관련 정보·도구·예시를 동적으로 불러와 모델 프롬프트에 포함하는 기법
- 모델이 필요한 자료를 실시간으로 조회해 더 정확하고 풍부한 정보를 활용할 수 있음
Fine-tuning Based Learning
- 특정 예시가 포함된 대규모 데이터셋으로 모델을 사전 학습(파인튜닝)하여, 사용자 쿼리를 받기 전에 이미 해당 영역에 대한 전문적 이해를 쌓도록 하는 방식
- 사전에 특정 도메인이나 작업에 특화된 지식을 습득하게 함으로써, 추론 정확도를 높일 수 있음
요리사의 비유를 통해 설명하듯, 간단한 레시피로 빠르게 요리를 만드는 'In-context Learning'부터, 재료와 레시피를 실시간으로 찾아 활용하는 'Retrieval-based In-context Learning', 그리고 새로운 요리를 미리 배워 숙달해두는 'Fine-tuning'을 적절히 조합하면, 모델이 보다 폭넓은 요구 사항에 대응하고, 정확하고 풍부한 답변을 생성할 수 있습니다.
Google에서 발행한 Agents 백서를 간단하게 정리해보았습니다. 아래 파일을 다운로드 받아 읽어보시면 예제 코드 및 자세한 내용을 확인하실 수 있습니다.
'개발 > LLM' 카테고리의 다른 글
| [논문 리뷰] Eliza: A Web3 friendly AI Agent OperatingSystem (0) | 2025.01.28 |
|---|---|
| [ChatGPT-4o][활용법] 로또 번호 빈도수 통계 분석 및 시각화 (0) | 2024.08.04 |
| [논문 리뷰][LLM] AIOS (2) | 2024.04.17 |
| [논문 리뷰] Toolformer: Language Models Can Teach Themselves to Use Tools (4) | 2024.02.21 |
| [ChatGPT][Plugin] 프롬프트 잘 작성하기 (34) | 2024.02.18 |



