Prompt Engineering Guide(https://www.promptingguide.ai/) 내용을 참고해서 작성하거나, 번역한 내용입니다.
Tree of Thoughts(ToT)
탐구나 전략적인 예측이 필요한 복잡한 작업들을 해결하기 위해, 기존의 프롬프팅 기법이나 단순한 프롬프팅 기법으로는 부족합니다. Yao et el. (2023)와 Long (2023)는 최근 Tree of Thoughts(ToT)의 개념을 제안하였습니다. 이 프레임워크는 생각의 사슬(chain-of-thought) 프롬프팅 기법을 일반화하며, 언어모델을 사용하여 일반적인 문제 해결을 위한 중간 단계 역할을 하는 생각에 대한 탐색을 촉진합니다.
2023.09.20 - [개발/프롬프트 엔지니어링] - Chain of Thought Prompting
Chain of Thought Prompting
Prompt Engineering Guide(https://www.promptingguide.ai/) 내용을 참고해서 작성하거나, 번역한 내용입니다. Chain of Thought Prompting (생각의 사슬 프롬프팅) LLM 에게 이유에 대해 설명하도록 만드는 방법입니다.
wide-shallow.tistory.com
ToT는 문제를 해결하기 위한 중간 단계로서 일관된 언어 시퀀스를 나타내는 Tree of Touhgts를 유지합니다. 이 접근 방법을 통해 LM은 신중한 추론 과정(deliberate reasoning process)을 거쳐 문제를 해결하기 위한 중간 생각들의 진행 과정을 자체적으로 평가할 수 있습니다. 그리고 이 LM이 생각을 생성하고 평가하는 능력은 탐색 알고리즘(예: BFS와 DFS)과 결합되어, 미리보기와 백트래킹으르 통해 생각의 체계적인 탐색을 가능하게 합니다.
ToT 프레임워크는 다음과 같습니다.

이미지 출처: Yao et el. (2023)
ToT를 사용할 때, 다른 작업들은 후보의 수와 생각/단계의 수를 정의하는 것을 요구합니다. 예를 들어, 논문에서 보여진 바와 같이, 24 게임(Game of 24)은 생각을 중간 방정식을 포함하는 3단계로 분해하는 수학적 추론 작업이 사용되었습니다. (24 게임은 다음 그림에서도 알 수 있듯이, 4, 9, 10, 13이 주어지면 $(10 - 4) \times (13 - 9)$와 같이 24를 만드는 방식을 찾는 게임입니다.)

이미지 출처: Yao et el. (2023)
24 게임 작업을 위해 ToT에서 너비 우선 탐색(BFS)를 수행하며 각 단계에서 최선의 $b=5$개의 후보를 유지합니다. LM은 각 생각 후보를 "확실함/아마도/불가능"으로 평가를 요청받습니다. 저자들은 "목표는 올바른 부분적 해결책을 촉진하는 것입니다. 몇 번의 예견 시험만으로 판단할 수 있고, "너무 크거나 작은" 상식에 기반하여 불가능한 부분 해결책을 제거하고, 나머지는 '아마도'로 유지합니다.""라고 말합니다. 각 생각에 대한 값은 3번 샘플링됩니다. 아래에 이 과정이 그림으로 나타나 있습니다.
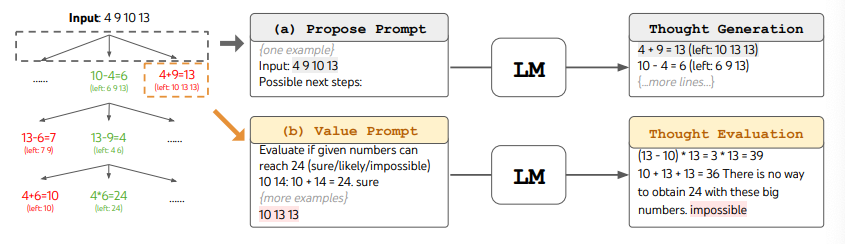
이미지 출처: Yao et el. (2023)
아래 그림에서 볼 수 있듯, ToT는 다른 프롬프팅 방법들에 비해 월등히 뛰어납니다. 기존 CoT 방법은 4%의 작업만 해결했지만, ToT 방법은 74%의 작업을 해결함을 보여줍니다.
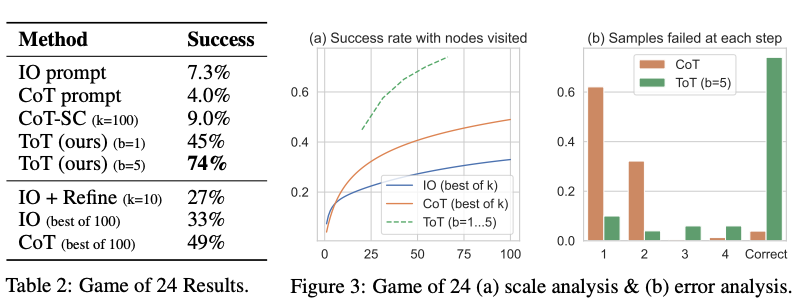
이미지 출처: Yao et el. (2023)
이곳과 이곳에서 코드 확인해 볼 수 있습니다.
높은 수준에서 보면, Yao et el. (2023)와 Long (2023)의 주요 아이디어는 비슷합니다. 두 연구 모두 다단계 대화를 통한 트리 검색을 통해 LLM의 복잡한 문제 해결 능력을 향상시킵니다. 주요 차이점 중 하나는 Yao et el. (2023)이 DFS/BFS/빔 탐색을 활용하는 반면, Long (2023)에서 제안하는 트리 검색 전략(즉, 언제 백트래킹을 하고, 몇 단계로 백트래킹을 하는지 등)은 강화 학습(RL)을 통해 훈련된 "ToT 컨트롤러"에 의해 주도됩니다. DFS/BFS/빔 탐색은 특정 문제에 한정되지 않는 일반적인 해결책 검색 전략(generic solution search strategies)입니다. 반면, RL을 통해 훈련된 ToT 컨트롤러는 새로운 데이터 세트 또는 자체 플레이(AlphaGo vs 무차별 검색)를 통해 학습할 수 있으므로 RL 기반의 ToT 시스템은 고정된 LLM으로도 계속해서 발전하고 새로운 지식을 배울 수 있습니다.
Hulbert (2023)은 Tree-of-Thought 프롬프팅을 제안했는데, 이는 ToT 프레임워크의 주요 개념을 간단한 프롬프팅 기법으로 적용하여 LLM이 단일 프롬프트에서 중간 생각을 평가하게 합니다. 샘플 ToT 프롬프트는 다음과 같습니다.
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they are wrong at any point then they leave.
The question is...
'개발 > LLM' 카테고리의 다른 글
| [ChatGPT][Plugin] PDF 요약 및 번역하기 (4) | 2024.02.12 |
|---|---|
| [Prompt Engineering][LLM] 랭체인(LangChain)이란? (6) | 2024.02.06 |
| ControlNet 이란? (2) | 2023.10.04 |
| Diffusion 모델 종류 및 예제 (0) | 2023.10.02 |
| QA using a search API (0) | 2023.09.24 |



