ControlNet 이란?
ControlNet은 이미지의 모양, 구성, 의미 등을 세밀하게 제어할 수 있도록 이미지 생성 모델에 조건부 제어를 추가하는 오픈소스 신경망입니다.
ControlNet 작동 방식
ControlNet은 두 개의 신경망으로 구성됩니다. 첫 번째 신경망은 사전 학습된 이미지 생성 모델이고, 두 번째 신경망은 조건부 신경망입니다. 첫 번째 신경망은 이미지의 저차원 벡터에서 고차원 픽셀 값을 생성하는 데 사용되고, 두 번째 신경망은 사용자가 제공한 조건에 따라 첫 번째 신경망의 출력을 조정하는 데 사용됩니다.
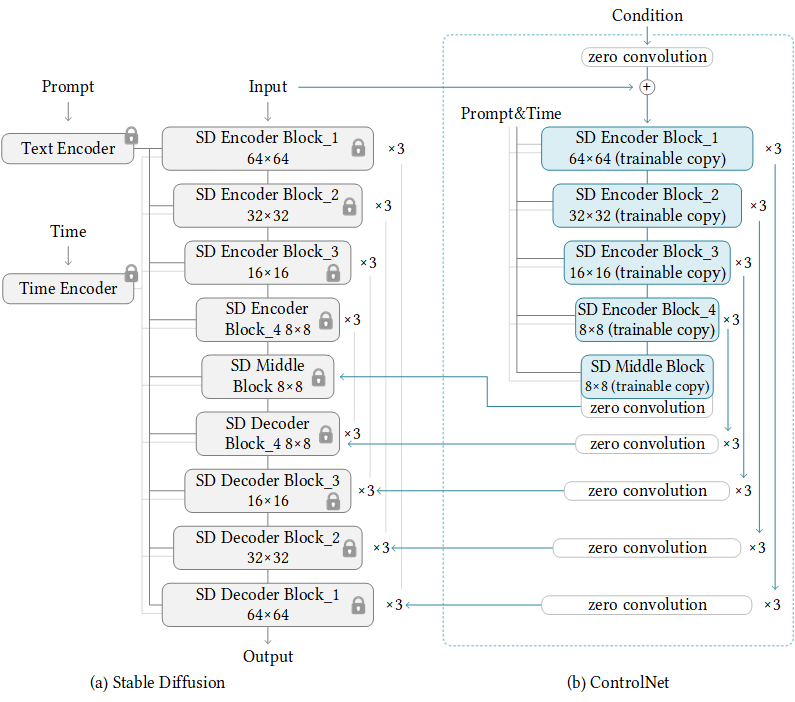
이미지 출처: lllyasviel/ControlNet
ControlNet 사용 예
ControlNet은 다음과 같은 경우에 사용될 수 있습니다.
- 사진의 배경을 바꾸기
도시 풍경 사진을 바다 풍경 사진으로 바꾸거나, 실내 사진을 야외 사진으로 바꿀 수 있습니다. - 이미지에 새로운 요소를 추가하기
사람의 얼굴에 안경이나 모자를 추가하거나, 동물의 그림에 움직임을 추가할 수 있습니다. - 특정 주제의 이미지 생성하기
만화 캐릭터의 이미지를 생성하거나, 꽃밭의 이미지, 또는 텍스트에 원하는 형태의 이미지를 넣어 생성할 수 있습니다.
ControlNet 사용하여 Text Effect 넣어보기
AUTOMATIC1111 WebUI를 이용하여 ControlNet을 설명하는 많은 글들이 있지만, 내부적으로 어떻게 동작하는지 알기 위해 Colab을 이용하여 ControlNet을 사용해보았습니다. 예제 코드를 작성할 때는 Hugging Face 사이트를 참고하였습니다.

이미지 출처: stable-diffusion-art 사이트
본문에서는 text effect를 넣을 수 있는 예를 아래 그림과 같이 구성해보겠습니다.
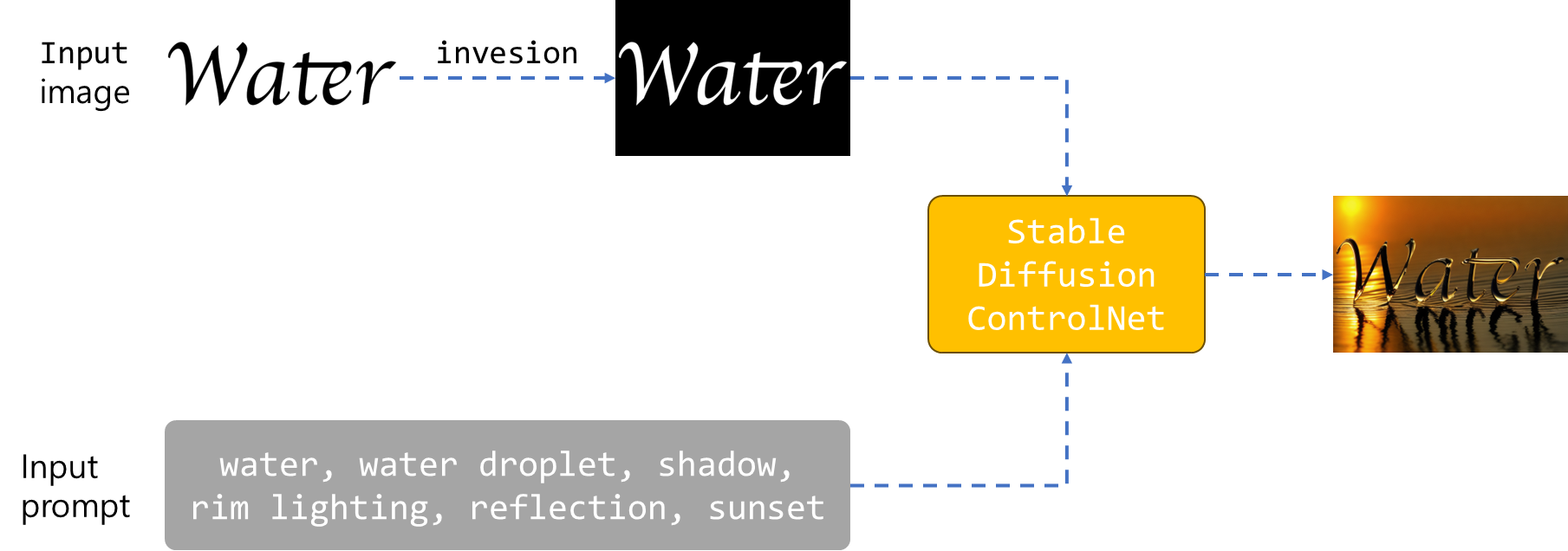
- ControlNet 모델: lllyasviel/control_v11f1p_sd15_depth
- Diffusion 모델: XpucT/Deliberate
- 입력 프롬프트: water, water droplet, shadow, rim lighting, reflection, sunset
먼저, Water 이미지를 반전시켜 배경이 검은색, 글자가 흰색이 되도록 만들어줍니다. 반전 처리를 하지 않은 경우는 아래와 같이 이미지가 생성됩니다.

이렇게 만들어주는 이유는 ControlNet 모델로 lllyasviel/control_v11f1p_sd15_depth 을 사용하는데, depth map 에서는 흰색이 더 가깝다는 의미임으로 글자가 더 가까이 보이게 하기 위해 반전 처리가 필요합니다.
아래와 같이 간단히 이미지 반전을 처리할 수 있습니다.
image = load_image("./water.png")
image = np.array(image)
image = 255 - image
water_inversion_image = Image.fromarray(image)
반전 처리를 한 이미지를 다음과 같이 StableDiffusionControlNetPipeline에 2번째 argument로 넣어줍니다.
output = pipe(
prompt,
water_inversion_image,
num_inference_steps=20,
generator=generator,
)
stable-diffusion-art 사이트에서 Deliberate v2 모델을 사용하여 이미지를 생성하였음으로 동일한 모델을 사용하여 이미지를 생성해보았습니다.

간단하지만, ControlNet을 사용하는 방법에 대해 알아보았고, 다른 3가지 diffusion 모델을 이용하여 생성한 이미지들과 비교해보겠습니다.
| Deliberate | stable-diffusion-v1-5 | anything-v3.0 | Realistic_Vision_V2.0 |
 |
 |
 |
 |
모델에 따라 조금씩 다른 이미지가 생성되는 것을 확인할 수 있습니다. 모델에 대해 더 자세히 알고 싶으면 아래 모델 페이지를 참고하세요.
Deliberate
Stable Diffusion v1.5
Stable diffusion v1.5는 Stability AI의 파트너인 Runway ML에서 2022년 10월에 공개한 모델로, v1.2를 기반으로 좀 더 학습시킨 모델입니다.
Anything v3
Anything v3 는 애니메이션 스타일 이미지를 생성하도록 훈련된 모델입니다. 현재 v5 모델을 다운로드 받아 사용할 수 있습니다.
Realistic Vision v2
버전 2.0의 경우 VAE와 함께 사용하는 것이 좋다고 합니다(생성 품질을 향상하고 파란색 아티팩트를 제거하기 위해). 현재 v5.1 모델을 다운로드 받아 사용할 수 있습니다.
'개발 > LLM' 카테고리의 다른 글
| [Prompt Engineering][LLM] 랭체인(LangChain)이란? (6) | 2024.02.06 |
|---|---|
| Tree of Thoughts (0) | 2023.10.09 |
| Diffusion 모델 종류 및 예제 (0) | 2023.10.02 |
| QA using a search API (0) | 2023.09.24 |
| Retrieval Augmented Generation(RAG) (0) | 2023.09.23 |



